Unleashing the Power of Serverless AI: Building an Intelligent Assistant with AWS Bedrock
The landscape of artificial intelligence (AI) and cloud computing is rapidly evolving. The marriage of serverless architecture and AI capabilities has given rise to innovative solutions that will transform how businesses operate. One such application is the development of a Serverless AI Assistant using the infrastructure of Amazon Web Services (AWS). In this blog post, we delve into some of the possibilities of this technology. We’ll explore its use case in business consulting, show an example architecture, and explain its benefits and potential future improvements.
The Use Case: AI Assistant for Business Consulting
Imagine an intelligent assistant that not only assists business consultants in navigating complex issues but leverages the power of AI to generate insightful and relevant content. This is precisely the use case we’re addressing – an AI Assistant tailored for business consulting. The goal is to enhance consultants’ efficiency with a tool that can analyze complex data, generate original and pertinent content, and ensure the originality of the content. Let’s dive into how this is achieved through AWS services.
Introduction to Serverless AI on AWS
Serverless computing has emerged as a game-changer, allowing developers to focus on code without the hassle of managing servers. AWS, a leading cloud provider, offers a suite of services that seamlessly integrates into a serverless architecture. The Serverless AI Assistant we’re discussing leverages AWS services to create a dynamic and scalable solution.
Architecture Overview: Unraveling the AWS Tapestry
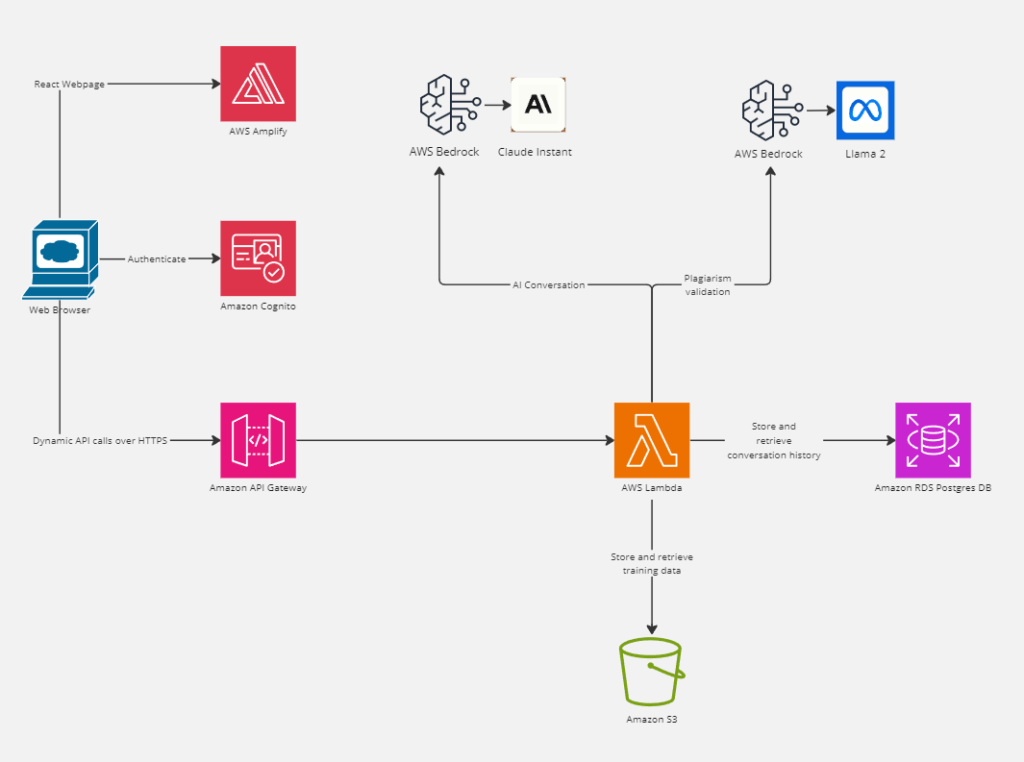
Firstly, AWS Amplify hosts the front end of our intelligent assistant. In our case, this is a user-friendly web-embedded application. Amplify seamlessly integrates with Amazon Cognito for secure user authentication. Once authenticated, users input their queries, which are then passed to the backend through API Gateway endpoints.
Here API Gateway acts as the gateway to our serverless architecture, efficiently managing the flow of requests. Each endpoint is connected to an AWS Lambda function, and here’s where the magic happens. Next, the Lambdas handle the interaction with AWS Bedrock, specifically the foundation model named Claude. Claude, armed with its deep learning capabilities, generates content in response to the user’s query.
To ensure the authenticity and originality of the content, another Bedrock foundation model, Llama 2, steps in. Llama 2 assesses the generated content, providing a confidence score of originality and conducting plagiarism checks. This multi-layered approach adds more assurance to the quality and integrity of the information delivered by our AI Assistant.
Once we vet and approve the conversation data, we can store it in an RDS database, ensuring persistence and accessibility. The entire architecture is fortified by AWS Identity and Access Management (IAM), which meticulously handles permissions for all services involved.
Finally, we can use S3 to store data that we can use to provide context for the models through Retrieval-Augmented Generation.
An Example
Here is an example of a simple way a Python Lambda can access Bedrock’s foundation model Claude to generate material:
import json
import boto3
# Bedrock client used to interact with APIs around models
bedrock = boto3.client(
service_name='bedrock',
region_name=<your_region>
)
# Bedrock Runtime client used to invoke and question the models
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name=<your_region>
)
def lambda_handler(event, context):
# Set up response object defaults
responseObject = {}
responseObject['headers'] = {
'Access-Control-Allow-Headers': '*',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Credentials': True,
'Access-Control-Allow-Methods': 'POST'
}
# Get body to form query
try:
if isinstance(event['body'], str):
content = json.loads(event['body'])
else:
content = event.get('body')
query = content['query']
except Exception as e:
responseObject['statusCode'] = 500
responseObject['body'] = 'Error: ' + str(e)
return(responseObject)
# Create prompt for fm
vPrompt = <prompt_engineeering>
vPrompt = vPrompt + query
# Default values for inference parameters
max_tokens_to_sample = 300
temperature = 0.5
top_k = 250
top_p = 0.5
# Check queryStringParameters for inference parameters
queryStringParameters = event.get('queryStringParameters')
if queryStringParameters is not None:
if 'max_tokens_to_sample' in queryStringParameters:
max_tokens_to_sample = int(queryStringParameters.get('maxTokensToSample'))
if 'temperature' in queryStringParameters:
temperature = float(queryStringParameters.get('temperature'))
if 'top_k' in queryStringParameters:
top_k = int(queryStringParameters.get('topK'))
if 'top_p' in queryStringParameters:
top_p = float(queryStringParameters.get('topP'))
# The payload to be provided to Bedrock
body = json.dumps({
'prompt':f'\n\nHuman:{vPrompt}\n\nAssistant:',
'max_tokens_to_sample': max_tokens_to_sample,
'temperature': temperature,
'top_k': top_k,
'top_p': top_p,
})
#modelId = 'anthropic.claude-v2'
modelId = 'anthropic.claude-instant-v1'
accept = 'application/json'
contentType = 'application/json'
response = bedrock_runtime.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
print(response_body.get('completion'))
# The response from the model now mapped to the answer
answer = response_body.get('completion')
responseObject['statusCode'] = 200
data = {'answer': answer}
responseObject['body'] =
json.dumps(data, default=str)
return(responseObject)
In the code above, we should write a prompt in place of <prompt_engineering>. The purpose of this prompt is to give context and instructions to the LLM. We can get the AI assistant to handle complex queries here by providing it with detailed context, describing the multiple inputs it will be receiving and what they mean, and what our expectation for its output should be, formatting included. For instance, you could tell the LLM that it is an AI assistant whose job is to generate movie screenplays. You can tell the model it will be provided with a setting, characters, and conflict (this information could be passed in through a JSON body). From those inputs, it will generate a part of a screenplay for a movie scene. You can give the model a short example of a screenplay and instruct it to format the screenplay it generates accordingly.
Benefits of the Architecture: A Symphony of Efficiency
- Scalability: The serverless architecture enables our AI Assistant to scale effortlessly based on demand. Whether handling a handful of queries or experiencing a surge in traffic, the system dynamically adjusts, ensuring optimal performance.
- Cost-Efficiency: With serverless computing, you pay for what you use. AWS Lambda, API Gateway, and other services follow a pay-as-you-go model, making it a cost-effective solution for businesses of all sizes.
- Security: AWS services are renowned for their robust security features. With Cognito handling user authentication, API Gateway securing the communication, and IAM managing permissions, our architecture is fortified against potential threats.
- Ease of Development: Serverless architecture abstracts away server management, allowing developers to focus solely on coding. This accelerates development cycles and facilitates quicker deployment of new features.
- Swappable Foundation Models and Adjustable Inference Parameters: With AWS Bedrock, swapping a foundation model is as easy as a few lines of code change. We could even derive the foundation model from the arguments we pass to the Lambda function. Likewise, each foundation model has inference parameters that control such things as randomness and diversity, length, and repetitions.
Future Improvements: Paving the Way for Advancements
While our Serverless AI Assistant is a testament to the current capabilities of AWS and serverless computing, there are areas for potential improvement:
- Enhanced AI Models: Continuous refinement and updating of the underlying AI models, such as Claude and Llama 2, will ensure the assistant stays at the forefront of AI advancements, delivering increasingly sophisticated and accurate results.
- Multiple FM Generation: We could use multiple foundation models in concert with one another to generate material. For instance, we could use Claude to generate text for a movie script scene while we use Stable Diffusion to generate storyboard images to accompany the text.
- Expanded Use Cases: We can extend the architecture to cater to diverse business domains. Customization options and adaptability will empower businesses to tailor the assistant to their specific needs.
- Training on Client Data: Fostering Personalization: Currently, our Serverless AI Assistant relies on pre-trained models like Claude and Llama 2 from AWS Bedrock. Future improvements to our assistant should empower clients to train these models with their proprietary data, enhancing the AI’s understanding of the client’s industry-specific nuances. We can achieve this through a process where clients upload their datasets to a dedicated training environment.
- Private Training Data: Safeguarding Client Information: Ensuring the privacy and security of client data during the training process is paramount. AWS can implement measures to designate client-specific training datasets as private, restricting access to these datasets solely within the client’s AWS account. This would prevent any unauthorized access, ensuring that the sensitive information within the training data remains confidential.
- Real-time Collaboration: Introducing real-time collaboration features could elevate the AI Assistant’s utility. Imagine multiple consultants collaborating through the assistant, generating a collective pool of insights.
Conclusion: A Glimpse into the Future
In conclusion, the amalgamation of serverless architecture and AWS services has birthed a revolutionary tool in the form of a Serverless AI Assistant for business consulting. This technology not only streamlines the workflow of consultants but also harnesses the power of AI to deliver insightful, original, and secure content. When we look ahead, the future holds the promise of continuous improvement, expanding capabilities, and the integration of AI into new frontiers. The journey towards AI-driven business efficiency has just begun, and AWS is paving the way.
A bit of that future is right in front of you. This blog post was generated with assistance from the technology stack discussed above.